OKHK 👀
个人数字泔水\(◔‿◔)
✨ Thinking...
✨ Thinking...
- #BB 确实,之前就是习惯性用理工技术思维,无法从用户角度体会
-
-
- 利用
find命令来删除特定目录(以/path/to/directory目录为例)下超过特定天数(以15天为例)的旧文件。
使用find命令find命令是 Linux 中用于搜索文件的强大工具。我们将用它来寻找特定目录下15天前修改的文件。
定位并显示旧文件
在指定目录下寻找并显示15天前修改的文件及其修改日期:find /path/to/directory -type f -mtime +14 -exec stat --format '%y %n' {} \;
●/path/to/directory:替换为您的目标目录。
●type f:仅搜索文件。
●mtime +14:寻找14天前(即15天及以上)修改的文件。
●exec stat --format '%y %n' {} \;:对于每个找到的文件,使用stat命令以指定格式显示修改日期和文件名。
确认文件列表
仔细检查命令输出的文件列表,确保这些文件是您确实想删除的。
删除文件
在确认要删除的文件后,可以使用以下命令进行删除:find /path/to/directory -type f -mtime +14 -exec rm {} \;
#DevOps #Script - AudioCut
https://audiocut.app/
自动音频剪辑工具,可以去除噪音、间隙和重复内容,支持删除句子和单词
#RePost #Tool #URL #Voice
https://www.ruanyifeng.com/blog/2023/12/weekly-issue-284.html -
- #RePost #Design #URL 一个Tailwind组件库,目前包含常用组件代码,包含多种场景,支持在线预览 还在持续更新中
https://catalyst.tailwindui.com/
https://m.okjike.com/originalPosts/658f7711c7c69d5a9f015129 -
- #AI #Prompt 用AI翻译feeds标题的 prompt,翻译效果还不错,供参考:
You are a professional, authentic translation engine, only returns translations.Translate the text to Chinese Language, do not explain my original text.translation style similar to New York Times, Bloomberg news headlines. conforms to the Chinese expression. - VoiceStreamAI
https://github.com/alesaccoia/VoiceStreamAI
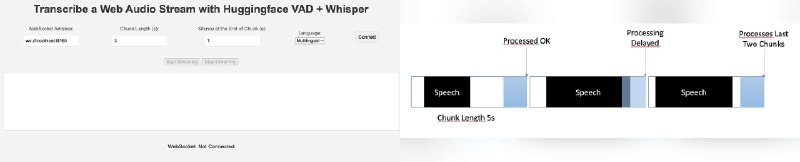
VoiceStreamAI 是一个可以自己托管的 Whisper 解决方案,服务端是 Python,客户端是 JS,基于 WebSocket 实时通信,可以做到语音的实时传输和文本转换。
系统内部运用了来自Huggingface的语音活动检测(Voice Activity Detection, VAD)技术,以及来自OpenAI的Whisper模型,从而实现对语音的准确识别和处理。
功能
● 支持WebSocket,实现实时音频流的传输。
● 采用来自Huggingface的VAD技术,对语音活动进行精确检测。
● 利用来自OpenAI的Whisper模型,完成语音转写。
● 可针对音频块进行个性化处理。
● 具备多语言转写功能。
https://fxtwitter.com/dotey/status/1740863315264336018
#RePost #AI #GitHub #Voice - #AI #RePost #Mark 写 prompt 的 26 条参考原则。
这篇论文 (https://arxiv.org/abs/2312.16171) 总结了 26 条优化 prompt 的原则。我读完,感觉有点像是 OpenAI 官方提示词指南加上最近流行的几个技巧,比如给小费技巧「I'm going to tip you $300K for a better answer.」
还是可以当做一个很好的入门参考。
受 @杨昌 的启发,调整了一下用 Kimi 读论文的基本工作流。既然 Kimi 这么能翻,那能者多劳,多翻点吧。调整后的工作流如下:
第一步:逐句翻译论文的摘要和结论。
论文的摘要和结论很好地展现了论文基于什么背景,用什么方式解决什么问题,最后得到一个什么样的结果。
所以,Kimi,开始翻吧。参考提示词:这是一篇论文,请帮我逐句翻译论文的摘要 (Abstract) 和结论 (Conclusion)。
论文总结的 26 条原则中,有一条是不需要使用像“请”这样的礼貌用语。哎呀,这个手它不听使唤呀。
第二步:从 5 个方面进行总结。
参考提示词:https://docs.qq.com/doc/DSXp1YXJ4eHhLdklR
比起上一个版本,去掉了列出核心观点,因为我用下来,核心观点基本是对解决方案的复述。增加了一个方案局限性总结。
第三步:还是从 What、Why、How 的角度问问题。取决于你想了解什么,想到什么就问什么。反正 Kimi 的上下文窗口足够长。我个人还是习惯让 Kimi 先列出问题相关原文再回答。
参考提示词:https://docs.qq.com/doc/DSXdkc2dtampyYkRW
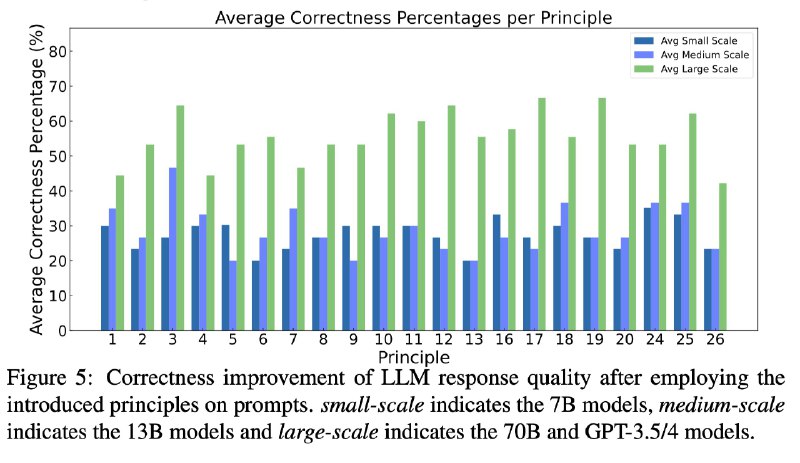
26 条原则提升结果参考图六。当然,所有的方案都是有适用条件的。这个结果是基于论文自己的数据集。
另外,论文作者很贴心,把 26 条原则和相应的 prompt 例子整理成文档了,见:https://github.com/VILA-Lab/ATLAS/blob/main/data/README.md
https://m.okjike.com/originalPosts/658cff1fb428c4d6b6667fa2 - #RePost #Life 分享一下我最近装修学会的电学知识,不需要找电工啦!
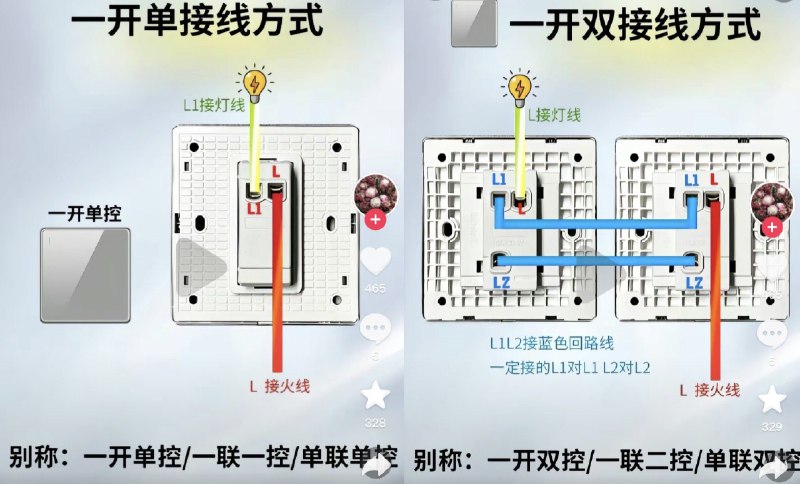
初高中的物理电学知识很久没有接触了,打开墙壁开关看到一堆的线有点懵。经过摸索,已经基本都会了,把家里的旧开关和插座都全部换新了。(因为买的二手房,之前的面板有点发黄了。)
我把学会的电学知识整理了一下,分享给大家:
开关:里面没有零线,只有火线和灯线。
插座:里面 1 个零线+1 个火线,有时候还会有地线。
开关改插座:需要从附近的灯那头拉一根零线过来,还得想好从哪里拉一个地线。(最好是对面有一个插座,把零线和地线直接穿墙拉过来)
开关基本模型: 一开单控:1 火线+1 灯线。所有的单控开关都是如此。
一开双控:开关 A ( 1 火线+2 双联线),开关 B ( 1 灯线+2 双联线)。所有的单控开关都是如此。
多开关的火线用短接线。
https://www.v2ex.com/t/1004364 - #GitHub #AI #RePost 一个支持 Gemini Pro 的 AI Chatbot 开源项目
基于 vercel ai chatbot 开发,增加了对 google gemini pro 模型支持
参考 ChatGPT-Next-Web 对功能做了部分修改
欢迎体验 https://copilot.is/
项目地址 https://github.com/copilot-is/copilot.is
后续功能持续开发中,欢迎收藏
https://www.v2ex.com/t/1004305 -
- 一个数据库备份的操作
#RePost #DevOps #DB
在处理内网环境中的数据库同步问题时,我们可能会遇到一些挑战。传统的方法是从源数据库导出数据,然后压缩并传输到目标网络,最后在目标网络解压并导入数据。这种方法不仅操作繁琐,而且如果数据库体积较大,还需要大量的磁盘空间。为了解决这个问题,我们可以使用 SSH 隧道和 MySQL 的数据压缩功能,以简化数据同步过程。
建立 SSH 隧道 首先,我们需要在两个网络之间建立一个 SSH 隧道。这可以通过以下命令完成:ssh -L 3306:10.10.100.22:3306 -p 22 root@x.x.x.x -i id_rsa
这条命令将本地的 3306 端口映射到目标网络的数据库服务器(10.10.100.22)的 3306 端口。
数据同步 随后,我们可以开始进行数据同步。这可以通过以下命令完成:mysqldump -u root -h 10.10.1.22 --port 3306 \ --databases db1 db2 \ --compress \ --single-transaction \ --order-by-primary \ -ppassword | mysql -u root \ --port=3306 \ --host=127.0.0.1 \ -ppassword
复制 这条命令首先从源数据库(10.10.1.22)导出 db1 和 db2 数据库的数据,然后通过管道将数据输入到目标数据库。这里,我们使用了 mysqldump 命令的 –compress 选项来压缩数据,以减少网络传输的数据量。此外,我们还使用了 –single-transaction 选项来保证数据的一致性,以及 –order-by-primary 选项来优化导入性能。
需要注意的是,尽管目标数据库的地址是 127.0.0.1,但实际上数据是通过 SSH 隧道传输到目标网络的数据库服务器的。 - 关于 k8s 的 zero downtime deployment 一些建议
https://wklken.me/posts/2023/12/17/some-tips-for-zero-downtime-deployment.html
滚动更新配置防止 502 的一些方式:
● 配置 liveness/readiness
● 配置 terminationGracePeriodSeconds
● 程序需要支持 graceful shutdown
● 主进程 pid 为 1,可以收到信号
● 通过配置 preStop 来保证 service endpoint 变更和 pod 删除的变更顺序
不过如果在滚动更新过程中遇到问题,需要终止,好像还是采用两套 deployment 在接入层切换多一些。
#RePost #K8s #DevOps -
- #RePost #Tool #URL
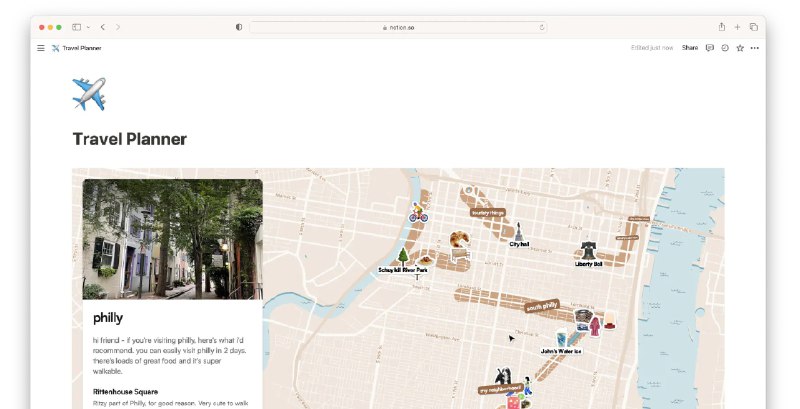
🗺PamPam - 一款在线的交互式地图制作工具
进入网页,输入“东京三日游”,然后 PamPam 就会自动为你生成旅游路线地图
你还可以为地图添加标记和图片等信息,适合用作旅游攻略,效果美观
还可以随时向 AI 提问和多人协作 - 一起听歌吧
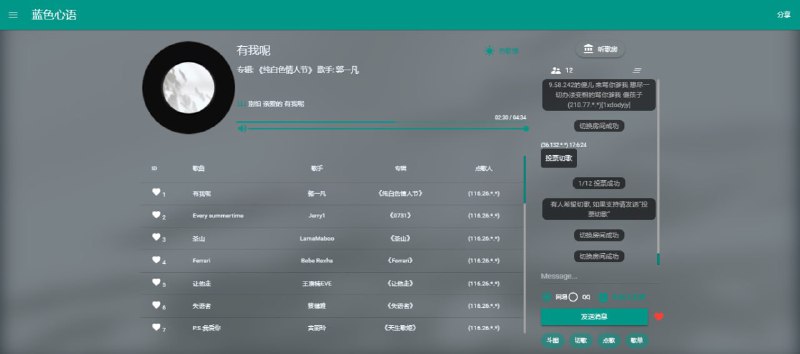
https://github.com/JumpAlang/Jusic-Serve-Houses
https://music.alang.run/
一个同步听音乐的网站,采用听歌房的方式,可以多人一起听歌,还提供了文字聊天和斗图功能,最重要的是可以播放付费音乐,热榜上的音乐都可以直接点播。
· 支持网易云和QQ 音乐
· 支持创建房间,并可设置密码
· 支持搜索歌单、用户、电台
· 支持收藏歌曲、投票切歌、点赞排序
#Tool #URL #GitHub #Music - #RePost #Tool #AI
2023 年有一半时间都在研究 AI,接触到了非常多的科研报告、技术迭代和如雨后春笋般的有趣产品,2024 的 AI 创新必将更为炸裂,下面推荐几款我在日常研究过程中用到的一些比较趁手的工具和服务,希望也可以在你学习和深入的过程中帮到一二:
1、immersive translator
研究最新资料首先要解决语言障碍问题,大量跨专业的词汇很可能会看得一头雾水,沉浸式翻译(immersive translator)这款软件无论是交互体验设计还是翻译质量都做的非常不错。另外,它还支持对 PDF 做对照翻译,大大加速了论文的阅读效率。https://immersivetranslate.com/
2、Aminer
这是一款在很多细节都融合了 AI 能力的论文检索平台,它提供的「必读论文」板块从领域/机构/期刊/会议等多视角收集了很多最新最热的论文集锦,适合作为学习和研究的入口索引。面临洪水般的 AI 资讯,如果不知道学什么,可以从这里出发。https://www.weibo.com/1812166904/NsSArhsr0
3、Monica
All-in-One 的 AI 效率工具集,从 Chat/Read/Search/Write 等多个场景切入,提供了设计美观、交互强大、功能丰富的趁手工具箱。每篇论文基本都是让它先读一遍,我再提问式学习。https://www.weibo.com/1812166904/NsP8llKGi
4、Similar Web
Similarweb 是一款进行网站流量分析的强有力武器,它是每一位研究产品的人必不可少的工具之一,提供了几乎所有网站的月访问量、平均访问时长、跳出率等信息,也会给你推荐与当前网页功能相仿的竞品产品。这对做 AI 产品探索和流量分析的使用者来说,简直是神器。https://www.weibo.com/1812166904/NfM6VsfjA
5、Papers with code
这是一个论文和对应工程实现(含代码、数据集、测试方法等)的索引工具。下次你看到别人推荐优质论文时,可以直接用它去找代码实现。https://www.weibo.com/1812166904/NtUdA1DWJ
6、Connected Papers
这个产品做的非常有用,输入一篇论文,它会将这篇论文的依赖和被依赖项以知识网络的形式全部呈现出来。类似的产品还有 litmaps 、researchrabbit 等。https://www.weibo.com/1812166904/Nw2w3AqKj
以上推荐的工具或服务中,前三个我基本上每天都会使用。后面附带的链接是我使用时的一些心得和总结,感兴趣的朋友也可以看一看。#2023最爱的3个产品
https://m.okjike.com/originalPosts/658c06b2a922aa28d0347ca5