OKHK 👀
个人数字泔水\(◔‿◔)
✨ Thinking...
✨ Thinking...
-
- #RePost #DevOps #GitHub #Docker
已经在用了,podman 比 docker 最大的优势有两点1
,原生支持 rootless ,没有 daemon ,管理起来很省心
2 ,原生支持 k8s yaml 文件定义 pod, deployment, stateful set, configmap, pvc 等等资源,意味着可以用 helm 来定义这些资源,渲染然后部署
3 ,cockpit 支持 podman ui ,不需要部署什么 portainer ,部署 cockpit 加 podman 插件就能通过网页管理 podman
这是我写的 ansible role ,用于部署 rootless podman
https://github.com/fsdrw08/SoloLab/tree/main/AnsibleWorkShop/runner/project/roles/ansible-podman-rootless-provision
至于如何在 podman 里部署应用,目前初步想法是用 podman 专用 helm chart+ terraform.
这里是我写的一些 podman 专用 helm chart
https://github.com/fsdrw08/helm-charts/tree/gh-pages/charts
podman 比 docker 最大的优势是没有守卫进程,节省资源说的是这个点,没了守护进程,但设置容器开机自启动的话,写 systemd 文件即可,podman 提供了 quadlet 来生成 systemd services 文件
目前最简单的方法应该是用 pack build ,dockerfile 都不用写,这工具能直接检测项目结构,自动选择适合的构建方式,我试过用 podman 运行 pack build 也没任何问题
https://www.v2ex.com/t/1005667 - 一个很不错的css风格 适用于 uptime-kuma
https://status.nanyaterus.com/
#Design #Script.title-flex { color: #ECF9FF !important; } .description[data-v-7d4a7f28] { text-align: center !important; font-size: 18px; font-weight: 900; color: #ECF9FF; } .overall-status[data-v-3bcb04ac] { text-align: center !important; } /* BG Animation */ body { background-size: 400% 400%; display: flex; flex-direction: column; align-items: stretch; justify-content: space-evenly; position: relative; overflow-x: hidden; } body::before, body::after { content: ""; width: 60vmax; height: 53vmax; position: absolute; background: rgba(255, 255, 255, 0.07); left: -20vmin; top: -20vmin; animation: morph 15s linear infinite alternate, spin 20s linear infinite; z-index: 1; will-change: border-radius, transform; pointer-events: none; } body::after { width: 70vmin; height: 70vmin; left: auto; right: -13vmin; top: auto; bottom: 10; animation: morph 10s linear infinite alternate, spin 26s linear infinite reverse; transform-origin: 20% 20%; } @-moz-keyframes Gradient { 0% { background-position: 0 50% } 50% { background-position: 100% 50% } 100% { background-position: 0 50% } } @keyframes Gradient { 0% { background-position: 0 50% } 50% { background-position: 100% 50% } 100% { background-position: 0 50% } } @keyframes morph { 0% { border-radius: 100% 60% 60% 40% / 70% 30% 70% 30%; } 100% { border-radius: 40% 60%; } } @keyframes spin { to { transform: rotate(1turn); } } -
- #RePost #Tool #Mark
给 2024 准备出海独立开发的朋友准备了一份 tips
最近梳理了下海外独立开发用到的技术和服务,服务尽量白嫖为主。希望能减少 2024 出海的朋友信息差。 分为技术栈,服务,营销工具三个部分。
以下是技术栈部分:
● 会什么用什么,千万不要重复学一门技术。
● 如果初学,建议按以下优先级,在做项目中学习
● vue 直接转 nuxt3, 否者选择 next.js ,这两个框架会未来将在你的产品构建,集成,部署,模板上带来巨大便利。
● 后端不会 java 就不要学 java 。
● 数据库白嫖云数据库,前期尽量不要自己搭建部署数据库。
原文链接
有补充的话可以留言,我将更新完善。
https://www.v2ex.com/t/1005011 - #BB 确实,之前就是习惯性用理工技术思维,无法从用户角度体会

-
-
- 利用
find命令来删除特定目录(以/path/to/directory目录为例)下超过特定天数(以15天为例)的旧文件。
使用find命令find命令是 Linux 中用于搜索文件的强大工具。我们将用它来寻找特定目录下15天前修改的文件。
定位并显示旧文件
在指定目录下寻找并显示15天前修改的文件及其修改日期:find /path/to/directory -type f -mtime +14 -exec stat --format '%y %n' {} \;
●/path/to/directory:替换为您的目标目录。
●type f:仅搜索文件。
●mtime +14:寻找14天前(即15天及以上)修改的文件。
●exec stat --format '%y %n' {} \;:对于每个找到的文件,使用stat命令以指定格式显示修改日期和文件名。
确认文件列表
仔细检查命令输出的文件列表,确保这些文件是您确实想删除的。
删除文件
在确认要删除的文件后,可以使用以下命令进行删除:find /path/to/directory -type f -mtime +14 -exec rm {} \;
#DevOps #Script - AudioCut
https://audiocut.app/
自动音频剪辑工具,可以去除噪音、间隙和重复内容,支持删除句子和单词
#RePost #Tool #URL #Voice
https://www.ruanyifeng.com/blog/2023/12/weekly-issue-284.html -
- #RePost #Design #URL 一个Tailwind组件库,目前包含常用组件代码,包含多种场景,支持在线预览 还在持续更新中
https://catalyst.tailwindui.com/
https://m.okjike.com/originalPosts/658f7711c7c69d5a9f015129 -
- #AI #Prompt 用AI翻译feeds标题的 prompt,翻译效果还不错,供参考:
You are a professional, authentic translation engine, only returns translations.Translate the text to Chinese Language, do not explain my original text.translation style similar to New York Times, Bloomberg news headlines. conforms to the Chinese expression. - VoiceStreamAI
https://github.com/alesaccoia/VoiceStreamAI
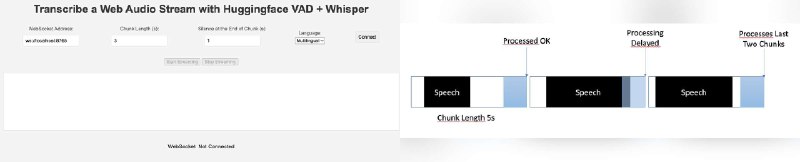
VoiceStreamAI 是一个可以自己托管的 Whisper 解决方案,服务端是 Python,客户端是 JS,基于 WebSocket 实时通信,可以做到语音的实时传输和文本转换。
系统内部运用了来自Huggingface的语音活动检测(Voice Activity Detection, VAD)技术,以及来自OpenAI的Whisper模型,从而实现对语音的准确识别和处理。
功能
● 支持WebSocket,实现实时音频流的传输。
● 采用来自Huggingface的VAD技术,对语音活动进行精确检测。
● 利用来自OpenAI的Whisper模型,完成语音转写。
● 可针对音频块进行个性化处理。
● 具备多语言转写功能。
https://fxtwitter.com/dotey/status/1740863315264336018
#RePost #AI #GitHub #Voice - #AI #RePost #Mark 写 prompt 的 26 条参考原则。
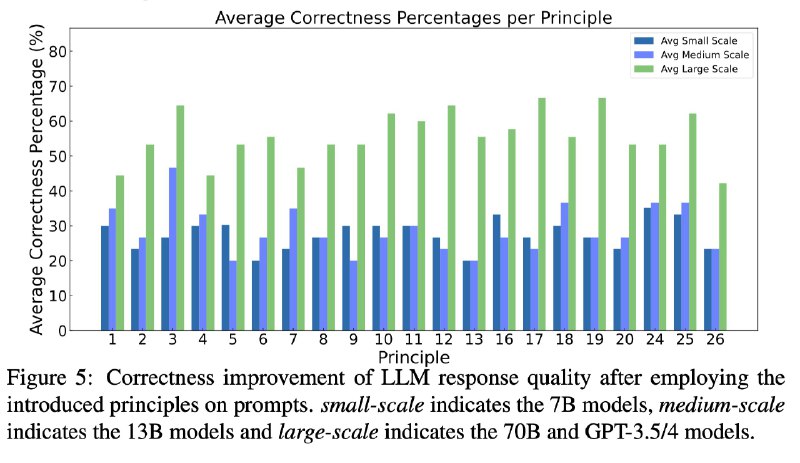
这篇论文 (https://arxiv.org/abs/2312.16171) 总结了 26 条优化 prompt 的原则。我读完,感觉有点像是 OpenAI 官方提示词指南加上最近流行的几个技巧,比如给小费技巧「I'm going to tip you $300K for a better answer.」
还是可以当做一个很好的入门参考。
受 @杨昌 的启发,调整了一下用 Kimi 读论文的基本工作流。既然 Kimi 这么能翻,那能者多劳,多翻点吧。调整后的工作流如下:
第一步:逐句翻译论文的摘要和结论。
论文的摘要和结论很好地展现了论文基于什么背景,用什么方式解决什么问题,最后得到一个什么样的结果。
所以,Kimi,开始翻吧。参考提示词:这是一篇论文,请帮我逐句翻译论文的摘要 (Abstract) 和结论 (Conclusion)。
论文总结的 26 条原则中,有一条是不需要使用像“请”这样的礼貌用语。哎呀,这个手它不听使唤呀。
第二步:从 5 个方面进行总结。
参考提示词:https://docs.qq.com/doc/DSXp1YXJ4eHhLdklR
比起上一个版本,去掉了列出核心观点,因为我用下来,核心观点基本是对解决方案的复述。增加了一个方案局限性总结。
第三步:还是从 What、Why、How 的角度问问题。取决于你想了解什么,想到什么就问什么。反正 Kimi 的上下文窗口足够长。我个人还是习惯让 Kimi 先列出问题相关原文再回答。
参考提示词:https://docs.qq.com/doc/DSXdkc2dtampyYkRW
26 条原则提升结果参考图六。当然,所有的方案都是有适用条件的。这个结果是基于论文自己的数据集。
另外,论文作者很贴心,把 26 条原则和相应的 prompt 例子整理成文档了,见:https://github.com/VILA-Lab/ATLAS/blob/main/data/README.md
https://m.okjike.com/originalPosts/658cff1fb428c4d6b6667fa2 - #RePost #Life 分享一下我最近装修学会的电学知识,不需要找电工啦!
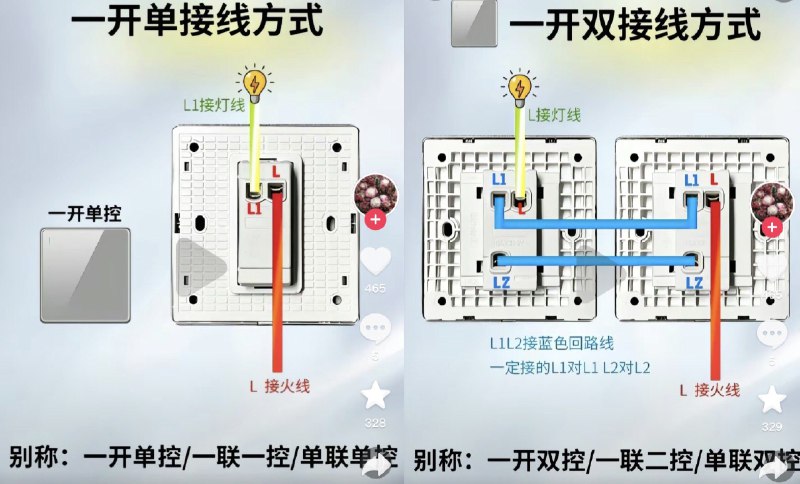
初高中的物理电学知识很久没有接触了,打开墙壁开关看到一堆的线有点懵。经过摸索,已经基本都会了,把家里的旧开关和插座都全部换新了。(因为买的二手房,之前的面板有点发黄了。)
我把学会的电学知识整理了一下,分享给大家:
开关:里面没有零线,只有火线和灯线。
插座:里面 1 个零线+1 个火线,有时候还会有地线。
开关改插座:需要从附近的灯那头拉一根零线过来,还得想好从哪里拉一个地线。(最好是对面有一个插座,把零线和地线直接穿墙拉过来)
开关基本模型: 一开单控:1 火线+1 灯线。所有的单控开关都是如此。
一开双控:开关 A ( 1 火线+2 双联线),开关 B ( 1 灯线+2 双联线)。所有的单控开关都是如此。
多开关的火线用短接线。
https://www.v2ex.com/t/1004364 - #GitHub #AI #RePost 一个支持 Gemini Pro 的 AI Chatbot 开源项目
基于 vercel ai chatbot 开发,增加了对 google gemini pro 模型支持
参考 ChatGPT-Next-Web 对功能做了部分修改
欢迎体验 https://copilot.is/
项目地址 https://github.com/copilot-is/copilot.is
后续功能持续开发中,欢迎收藏
https://www.v2ex.com/t/1004305 -
- 一个数据库备份的操作
#RePost #DevOps #DB
在处理内网环境中的数据库同步问题时,我们可能会遇到一些挑战。传统的方法是从源数据库导出数据,然后压缩并传输到目标网络,最后在目标网络解压并导入数据。这种方法不仅操作繁琐,而且如果数据库体积较大,还需要大量的磁盘空间。为了解决这个问题,我们可以使用 SSH 隧道和 MySQL 的数据压缩功能,以简化数据同步过程。
建立 SSH 隧道 首先,我们需要在两个网络之间建立一个 SSH 隧道。这可以通过以下命令完成:ssh -L 3306:10.10.100.22:3306 -p 22 root@x.x.x.x -i id_rsa
这条命令将本地的 3306 端口映射到目标网络的数据库服务器(10.10.100.22)的 3306 端口。
数据同步 随后,我们可以开始进行数据同步。这可以通过以下命令完成:mysqldump -u root -h 10.10.1.22 --port 3306 \ --databases db1 db2 \ --compress \ --single-transaction \ --order-by-primary \ -ppassword | mysql -u root \ --port=3306 \ --host=127.0.0.1 \ -ppassword
复制 这条命令首先从源数据库(10.10.1.22)导出 db1 和 db2 数据库的数据,然后通过管道将数据输入到目标数据库。这里,我们使用了 mysqldump 命令的 –compress 选项来压缩数据,以减少网络传输的数据量。此外,我们还使用了 –single-transaction 选项来保证数据的一致性,以及 –order-by-primary 选项来优化导入性能。
需要注意的是,尽管目标数据库的地址是 127.0.0.1,但实际上数据是通过 SSH 隧道传输到目标网络的数据库服务器的。