马拉赫塞斯国家公园,马拉尼昂州,巴西 (© thanosquest/Shutterstock)
4K原图:https://www.bing.com/th?id=OHR.LencoisMaranhao_ZH-CN8194406488_UHD.jpg
mobilegestalt 文件。




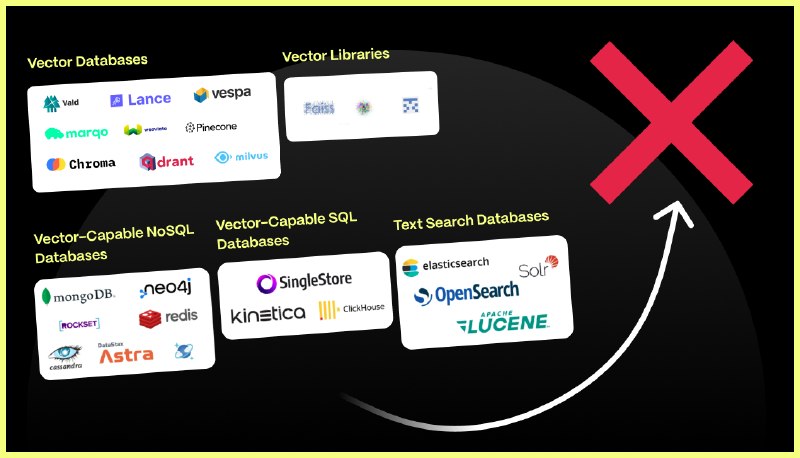
专用向量数据库早在几年前就出现了,比如 Milvus,主要针对的是非结构化多模态数据的检索。例如以图搜图(拍立淘),以音搜音(Shazam),用视频搜视频这类需求;PostgreSQL 生态的 pgvector,pase 等插件也可以干这些事。总的来说,算是个小众需求,一直不温不火。
向量数据库是一个伪需求吗?答案是:向量的存储与检索是真实需求,而且会随着AI发展水涨船高,前途光明。但这和专用的向量数据库并没有关系 —— 加装向量扩展的经典数据库会成为绝对主流,而**专用的向量数据库是一个伪需求**。
在绝大多数情况下,使用专用向量数据库的弊都要远远大于利:数据冗余、 大量不必要的数据搬运工作、分布式组件之间缺乏一致性、额外的专业技能带来的复杂度成本、学习成本、以及人力成本、 额外的软件许可费用、极其有限的查询语言能力、可编程性、可扩展性、有限的工具链、以及与真正数据库相比更差的数据完整性和可用性。用户唯一能够期待的收益通常是**性能** —— 响应时间或吞吐量,然而这个仅存的“优点”很快也不再成立了…
"You're building a RAG system, and your team uses Pinecone as a vector database to store and search embeddings. But you can't just use Pinecone—your text data doesn't fit well into Pinecone's metadata, so you're also using DynamoDB to handle those blobs and application data. And for lexical search, you needed OpenSearch. Now you're juggling three systems, and syncing them is a nightmare."
Vector databases treat embeddings as independent data, divorced from the source data from which embeddings are created, rather than what they truly are: derived data. By treating embeddings as independent data, we’ve created unnecessary complexity for ourselves.
In this post, we'll propose a better way: treating embeddings more like database indexes through what we call the **"vectorizer"** abstraction. This approach automatically keeps embeddings in sync with their source data, eliminating the maintenance costs that plague current implementations.