llms.txt 文件规范
https://llmstxt.org
大语言模型 (LLM) 越来越多地依赖网站信息,但面临一个关键限制:上下文窗口太小,无法处理大多数网站的全部内容。将复杂的 HTML 页面(包含导航、广告和 JavaScript)转换为 LLM 友好的纯文本既困难又缺乏精确性。
为了帮助 LLM 更有效地获取网站信息,本文提出了一种
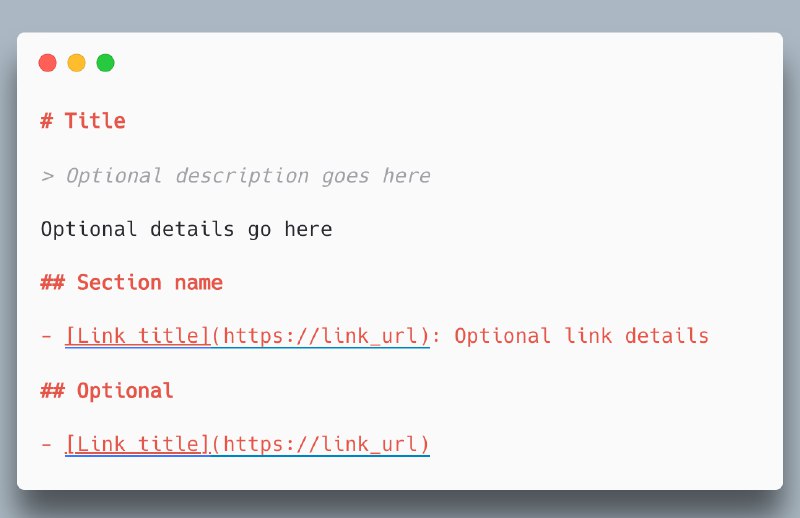
1. 标题 (H1): 项目或网站名称(必填)
2. 摘要 (blockquote): 项目简要总结,包含理解文件其他部分的关键信息
3. 详细描述 (Markdown): 包含项目详细描述和解释如何解读提供文件的更多说明,无需包含标题
4. 文件列表 (H2 + Markdown 列表): 包含指向更详细信息的 URL,每个 URL 都有一个描述性标题,格式为
#AI #Doc #URL
https://llmstxt.org
大语言模型 (LLM) 越来越多地依赖网站信息,但面临一个关键限制:上下文窗口太小,无法处理大多数网站的全部内容。将复杂的 HTML 页面(包含导航、广告和 JavaScript)转换为 LLM 友好的纯文本既困难又缺乏精确性。
为了帮助 LLM 更有效地获取网站信息,本文提出了一种
llms.txt 文件规范,该文件包含特定格式的 Markdown 信息,供 LLM 轻松读取。llms.txt 文件包含项目/网站名称、简要摘要、详细描述以及指向更详细文档的链接。它采用 Markdown 格式,方便人类和 LLM 阅读,同时允许使用固定处理方法(例如,解析器和正则表达式)。此外,建议网站在与 LLM 有关的信息页面上提供对应的 .md 文件,以便 LLM 更方便地获取信息。llms.txt 文件的结构清晰,包含以下部分:1. 标题 (H1): 项目或网站名称(必填)
2. 摘要 (blockquote): 项目简要总结,包含理解文件其他部分的关键信息
3. 详细描述 (Markdown): 包含项目详细描述和解释如何解读提供文件的更多说明,无需包含标题
4. 文件列表 (H2 + Markdown 列表): 包含指向更详细信息的 URL,每个 URL 都有一个描述性标题,格式为
[标题](URL),之后可以跟详细说明或注释。可选的“Optional”部分用于包含可跳过的辅助信息。llms.txt 文件规范旨在与当前 web 标准兼容,可与站点地图和 robots.txt 文件协同工作。它提供 LLM 友好的页面概览,补充 robots.txt,并可引用站点上的结构化数据标记,帮助 LLM 理解上下文。llms.txt 文件主要用于在用户主动请求信息时(例如,在项目中包含编码库文档,或向聊天机器人寻求信息),而不是用于训练。该规范鼓励简洁明了的语言,准确的链接描述,避免模棱两可或不明确的术语。#AI #Doc #URL