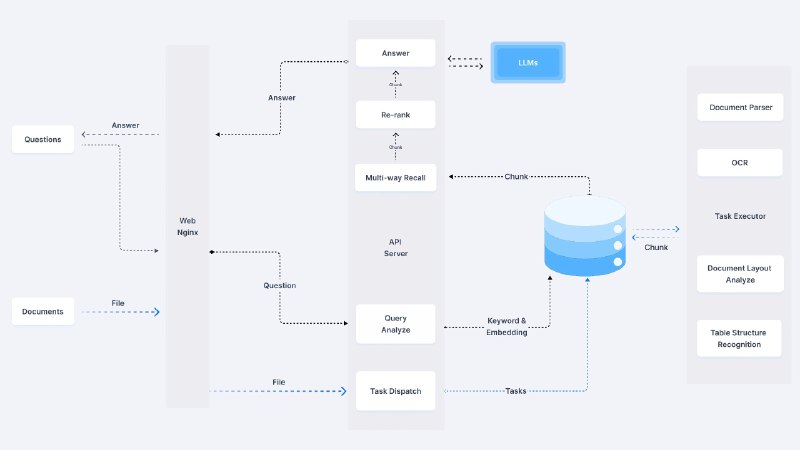
“弱智吧”不收弱智,成最佳中文AI训练语料!4月4日,“弱智吧”突然在中文AI领域刷屏,中科院用各大社交平台的数据,作为中文AI语料数据进行训练,结果发现“弱智吧”居然是最棒的中文语料,在多项测试中取得最高分!
目前LLM大型语言模型中,英文语料占到大多数,而中文数据集此前多半是先从英文翻译再进行训练,很多大模型的中文效果比英文差,为了调侃AI,许多人也常常拿弱智吧的问题去挑战AI。为了更好地满足中文大模型的需求,中科院联合多所大学利用中文数据集来训练中文大模型。
首先,团队直接找到某乎、某瓣等社交网络平台,爬取数据并进行标注,打造了全新的中文指令微调数据集COIG-CQIA,再用这些数据集来训练零一万物开源大模型,并用GPT4在BELLE-Eval测试集上打分。
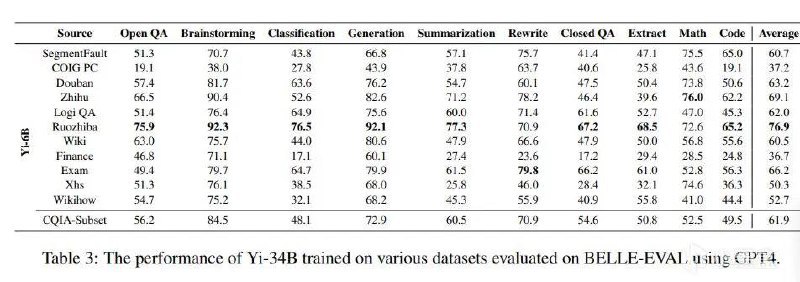
在340亿参数版本的Yi-34B下,弱智吧的分数非常突出,可以说是一骑绝尘,在问答、分类、生成、总结、摘要和代码上均取得极高的分数,数学某乎分数最高76分,但弱智吧也取得了72.6分的高分,最终均分76.9分遥遥领先!
弱智吧的出色成绩也引起了大量的讨论,对比其他专业的技术问答社区,弱智吧的数据集其实更加精炼有效,提高模型的逻辑推理能力,而且“弱智”的方向十分多元,文本质量极高,从而提高了模型性能。
而COIG-CQIA,也成为目前相对来说相当高质量的中文指令微调数据集,收集了来自各种来源如社交媒体、百科知识、考试题库等大量高质量的中文指令,弱智吧的出色表现,出在高质量中文知识学习方面的潜力,也给我们带来更多深入的思(乐)考(子)。
#RePost #AI link